
In a nutshell
No doubt, large language models (LLM) are a huge help for researching topics, generating summaries and ease processes of our daily student life. But when it comes to the reliability of its output, vigilance is due.
LLMs are trained on large datasets from various sources. These datasets can contain inaccuracies, biases, or outdated information, which the model may unintentionally use to generate responses. The model does not “know” facts like a human being – instead, it generates word after word based upon probabilities and patterns in the data it has seen. Because of this mechanism, LLMs can produce outputs that sound convincing but are factually incorrect.
There are many reasons, why LLMs hallucinate. On one hand, an AI can only generate information based on input and if the input is wrong or biased, one can’t expect a correct output. Training patterns and calibrations in the algorithm do also influence the outcome.
The need of fact checks with real sources is necessary, when one wants to pass on AI generated information. Even experts in their field can be misled, as information generated by LLMs seem plausible, coherent, and confident. This has nothing to do with the intelligence of the users, but rather due to how human brains are wired. The illusory truth effect, cognitive heuristic (also called mental shortcuts) and other psychological effects get the better of us.
Which mechanisms cause LLM hallucination?
There are over 70’000 hits, when you search scientic literature writing about hallucination in LLM. It seems like there’s a consensus on classification and sources of LLM hallucination.
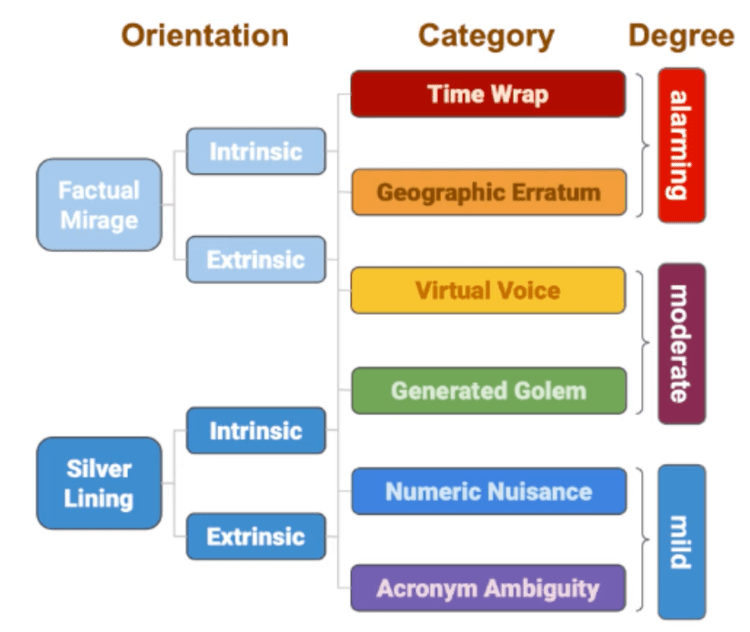
They are classified into intrinsic and extrinsic types:
- Intrinsic Hallucinations occur when the model’s output conflicts with the input data. For instance, if contradictory information is present in the training data, the LLM may generate inconsistent responses.
- Extrinsic Hallucinations happen when the model produces information that cannot be verified by the input data. For example, when the LLM provides a citation to a non-existent source or invents a plausible-sounding fact.
Hallucinations can occur from several sources:
- Misinformation and Bias in Training Data: If the training data includes incorrect or biased information, the model may replicate these errors.
- Outdated Knowledge: LLMs trained on old datasets may produce outputs based on obsolete information, leading to hallucinations.
- Training and Calibration: The settings and parameters used during training can also influence the model’s tendency to hallucinate. More creative settings increase the risk of fabricating information.
In literature, hallucinations are further categorized into specific types, such as factual mirage and faithfulness hallucination:
- Factual Mirage: The model generates outputs that sound factual but are incorrect.
- Faithfulness Hallucination: The output deviates from the original input source, introducing inaccuracies.
If you’re more of a visual type, this diagram might help you understanding it better. Rawte et al., EMNLP 2023 even categorized the severity of hallucinations into alarming, moderate and mild.
Luckily, LLM developers are aware of hallucinations and different tools to mitigate it were developed and research is being carried out further to keep it at bay. But some sources, say that hallucinations will always occur to a certain degree, because this is how LLMs process data.
What consequences do these hallucinations bring?
Hallucinations in LLMs can have serious consequences, especially in critical sectors such as healthcare, law, and education. Four categories pop up immediately when thinking of consequences. Would you agree? Do you have other concerns? Share it in the comments!
Propagation of false information: When LLMs generate incorrect but plausible-sounding information, it can spread quickly through social media, news, or even academic publications. This misinformation can shape public opinion, foster distrust, and amplify societal divides.
Wrong diagnoses in healthcare: In healthcare, hallucinations can be life threating. Imagine an AI recommending an incorrect diagnosis or treatment based on a fabricated study. Such errors can lead to harmful medical decisions, increased costs, and loss of trust in AI tools.
Ethical Implications: There are ethical concerns about the use of hallucinating LLMs. Hallucinations blur the lines between fact and fiction, which can undermine trust in AI-generated content. This lack of trust threatens informed decision-making and public confidence in technological advancements Furthermore, the propagation of biased or discriminatory information can have severe societal impacts. Furthermore, there are concerns about AI models maintaining historical biases and stereotypes present in their training data, leading to discrimination and reinforcing unethical viewpoints.
Societal Risks: The societal impact of hallucinations goes beyond individual misinformation. Hallucinations can contribute to the undermining of public discourse by fuelling the spread of disinformation produced by malicious actors, such as discreditable deepfakes or cyber fraud. With the increasing integration of AI systems into everyday life, there is also a growing potential for these illusions to influence public perception and social norms, requiring careful monitoring and ethical considerations in their use.
Which psychological effects are responsible, for humans having a hard time detecting LLM hallucinations?
LLMs are usually designed, to generate output in a style which is to the liking of the user. This should retain the user, rather than losing them to another provider. Furthermore, the generated output is presented in a way, that looks plausible and confident. When for example information is correct for a very closely related topic, but not for the one asked for in a prompt, hallucinated output can appear coherent, even to experts. But this also makes it harder for users to detect hallucinations without a thorough fact check. So what does science say, why we’re fooled by AI?
Cognitive Biases: Humans rely on cognitive shortcuts to process information quickly. These biases make us prone to believing plausible-sounding but incorrect information. Common biases include:
- Confirmation Bias: The tendency to favor information that confirms one’s existing beliefs.
- Availability Bias: Overestimating the truth of information that is easy to recall.
The Illusory Truth Effect describes how people are more likely to believe a statement if they hear it repeatedly, regardless of its accuracy. This makes it harder for users to recognize hallucinations when they sound familiar or are confidently presented by an LLM.
Social Influences impact the user’s perception and contribute to the spread of false information. People are more likely to trust information if others in their social group believe it, even if it is incorrect.
- Social proof: People copy the actions and behaviors of others, assuming that if many people are doing something, it must be the right or desirable thing to do.
- Groupthink: When a group of people prioritizes consensus and harmony over critical thinking and individual opinions.
- echo chambers: environment (especially online) where people are exposed only to information or opinions that align with their existing beliefs. This reinforces their biases and limits exposure to diverse perspectives.
Emotional Factors like fear, anger, or excitement can cloud judgment. Content that evokes strong emotions is more likely to be shared and believed, even if it is inaccurate.
And what do I think about it?
Honestly speaking, I’m thrilled by the possibilities which AI brings to the world. And surely, the chances of hallucinations become smaller and smaller with tools for mitigation. BUT… humans are very eager to staying in their psychological comfort zone. Malicious voices would say, humans are dumb or lazy, and this is even how I was socialized, but I decided to believe in a, more good-spirited philosophy on life. Early on in my professional training, I learned: SHIT IN = SHIT OUT. This also applies to large language models. Often I hear complaints about how the world was better in the “good old days” and that the dangers, resulting from biased thought propagation weren’t present back then. But let’s be honest, before click-rates, there were print runs, to be increade. And still today, news portals lie on an hourly basis. – I believe in the good in people. We need to draw attention to topics, which are relevant, educate people and propagate an open discourse.
Let’s wrap it up
Hallucinations in LLMs pose a significant challenge to the reliability and trustworthiness of AI-generated content. Understanding the mechanisms behind these hallucinations, the risks they pose, and the psychological factors that make them hard to detect can help users navigate the complex landscape of AI tools more effectively. While mitigation strategies are being developed, users must remain vigilant and critical in evaluating AI outputs to prevent the spread of misinformation.
Emanuel Hitz
About the author
Emanuel has a curious mind and likes exploring the 1000 topics, which spark up, when he hears about a subject which captivates his interest. His current studies are on preneurial approaches for regenerative food systems. He loves linking these with his expertise in industrial food production, supply networks and human interaction in order to combining different theories and applying them into reality.
Titel image source: AI hallucinating through a LLM maze (generated with adobe firefly)
If you like the picture, I generated it with adobe firefly. Here’s the prompt for the picture: A surrealistic 1930’s artwork depicting an androgynous robot made entirely of computer chips and circuits, walking in a maze-like a “Large Language Model” with brutalistic architecture. The robot’s head is a processor chip, and colorful, glitchy data streams steam out of its head. The maze has many corners and dead ends. The atmosphere is dreamlike and psychedelic, representing AI hallucinations and distorted information flow. The scene combines technology, surrealism, and the metaphor of a hallucinating AI which is lost. High detail, surrealistic, and glitch effects.
Style: psychedelic, surrealistic, cyber-matrix, surreal lighting
